1 4 2 1 Relations
Le modèle relationnel. ⅓ : relations et nuplets¶
Qu'est-ce donc que ce fameux "modèle relationnel" ? En bref, c'est un ensemble de résultats scientifiques, qui ont en commun de s'appuyer sur une représentation tabulaire des données. Beaucoup de ces résultats ont débouché sur des mises en œuvre pratique. Ils concernent essentiellement deux problématiques complémentaires :
- La structuration des données. Comme nous allons le voir dans ce chapitre, on ne peut pas se contenter de placer toute une base de données dans une seule table, sous peine de rencontrer rapidement des problèmes insurmontables. Une base de données relationnelle, c'est un ensemble de tables associées les unes aux autres. La conception du schéma (structures des tables, contraintes sur leur contenu, liens entre tables) doit obéir à certaines règles et satisfaire certaines propriétés. Une théorie solide, la normalisation, a été développée et permet de s'assurer que l'on a construit un schéma correct.
- Les langages d'interrogation. Le langage SQL que nous connaissons maintenant est issu d'efforts intenses de recherche menés dans les années 70-80. Deux approches se sont dégagées : la principale est une conception déclarative des langages de requêtes, basées sur la logique mathématique. Avec cette approche on formule (c'est le mot) ce que l'on souhaite, et le système décide comment calculer le résultat. La seconde est de nature plus procédurale, et identifie l'ensemble minimal des opérateurs dont le système doit disposer pour évaluer une requête. C'est cette seconde approche qui est utilisée en interne pour construire des programmes d'évaluation.
Dans ce chapitre nous étudions la structure du modèle relationnel, soit essentiellement la représentation des données, les contraintes, et les règles de normalisation qui définissent la structuration correcte d'une base de données. Deux exemples de bases, commentés, sont donnés en fin de chapitre. Les chapitres suivants seront consacrés aux différents aspects du langage SQL.
Relations et Nuplets¶
Supports complémentaires
L'expression "modèle relationnel" a pour origine (surprise !) la notion de relation, un des fondements mathématiques sur lesquels s'appuie la théorie relationnelle. Dans le modèle relationnel, la seule structure acceptée pour représenter les données est la relation.
Qu'est-ce qu'une relation ?¶
Étant donné un ensemble d'objets \(O\), une relation (binaire) sur \(O\) est un sous-ensemble du produit cartésien \(O \times O\). Au cas où vous l'auriez oublié, le produit cartésien entre deux ensembles \(A \times B\) est l'ensemble de toutes les paires possibles constituées d'un élément de \(A\) et d'un élément de \(B\).
Dans le contexte des bases de données, les objets auxquels on s'intéresse sont des valeurs élémentaires comme les entiers \(I\), les réels (ou plus précisément les nombres en virgule flottante puisqu'on ne sait pas représenter une précision infinie) \(F\), les chaînes de caractères \(S\), les dates, etc. La notion de valeur élémentaire s'oppose à celle de valeur structurée : il n'est pas possible en relationnel de placer dans une cellule un graphe, une liste, un enregistrement.
On introduit de plus une restriction importante : les relations sont finies (on ne peut pas représenter en extension un ensemble infini avec une machine).
L'ensemble des paires constituées des noms de département et et de leur numéro de code est par exemple une relation en base de données : c'est un ensemble fini, sous-ensemble du produit cartésien \(S \times I\).
La notion de relation binaire se généralise facilement. Une relation ternaire sur \(A\), \(B\), \(C\) est un sous-ensemble fini du produit cartésien \(A \times B \times C\), qui lui même s'obtient par \((A \times B) \times C\). On peut ainsi créer des relations de dimension quelconque.
Définition : relation
Une relation de degré n sur les domaines \(D_1, D_2, \cdots, D_n\) est un sous-ensemble fini du produit cartésien \(D_1 \times D_2 \times \cdots \times D_n\)
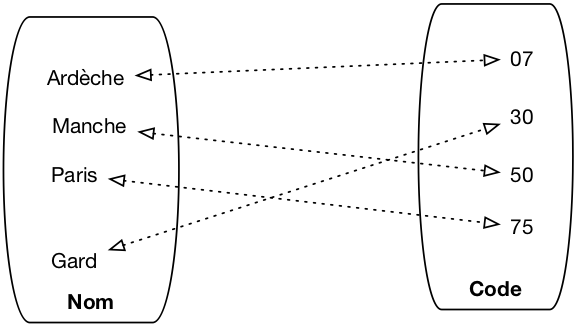
fig. 5 Une relation binaire représentée comme un graphe
Une relation est un objet abstrait, on peut la représenter de différentes manières. Une représentation naturelle est le graphe comme le montre la figure 5. Une autre structure possible est la table, qui s'avère beaucoup plus pratique quand la relation n'est plus binaire mais ternaire et au-delà.
| nom | code |
|---|---|
| Ardèche | 07 |
| Gard | 30 |
| Manche | 50 |
| Paris | 75 |
Dans une base relationnelle, on utilise toujours la représentation d’une relation sous forme de table. À partir de maintenant nous pourrons nous permettre d’utiliser les deux termes comme synonymes.
Les nuplets¶
Un élément d'une relation de dimension n est un nuplet \((a_1, a_2, \cdots, a_n)\). Dans la représentation par table, un nuplet est une ligne. Là encore nous assimilerons les deux termes, en privilégiant toutefois nuplet qui indique plus précisément la structure constituée d'une liste de valeurs.
La définition d'une relation comme un ensemble (au sens mathématique) a quelques conséquences importantes :
- L'ordre des nuplets est indifférent car il n'y a pas d'ordre dans un ensemble ; conséquence pratique : le résultat d'une requête appliquée à une relation ne dépend pas de l'ordre des lignes dans la relation.
- On ne peut pas trouver deux fois le même nuplet car il n'y a pas de doublons dans un ensemble.
- Il n'y a pas (en théorie) de "cellule vide" dans la relation ; toutes les valeurs de tous les attributs de chaque nuplet sont toujours connues.
Dans la pratique les choses sont un peu différentes pour les doublons et les cellules vides, comme nous le verrons.
Le schéma¶
Et, finalement, on notera qu'aussi bien la représentation par graphe
que celle par table incluent un nommage de chaque dimension (le nom du
département, son code, dans notre exemple). Ce nommage n'est pas
strictement indispensable (on pourrait utiliser la position par
exemple), mais s'avère très pratique et sera donc utilisé
systématiquement.
On peut donc décrire une relation par :
- le nom de la relation ;
- un nom (distinct) pour chaque dimension, dit nom d'attribut, noté \(A_i\) ;
- le domaine de valeur (type) de chaque dimension, noté \(D_i\).
Cette description s´écrit de manière concise
\(R (A_1: D_1, A_2: D_2, \cdots, A_n: D_n)\), et on l´appelle le schéma
de la relation. Tous les \(A_i\) sont distincts, mais on peut bien entendu
utiliser plusieurs fois le même type. Le schéma de notre table des
départements est donc Département (nom: string, code: string). Le
domaine de valeur ayant relativement peu d'importance, on pourra
souvent l'omettre et écrire le schéma Département (nom, code). Il est
d'aileurs relativement facile de changer le type d'un attribut sur une
base existante.
Et c'est tout ! Donc en résumé,
Définition : relation, nuplet et schéma
1. Une relation de degré n sur les domaines \(D_1, D_2, \cdots, D_n\) est un sous-ensemble fini du produit cartésien \(D_1 \times D_2 \times \cdots \times D_n\). 2. Le schéma d'une relation s'écrit \(R (A_1: D_1, A_2: D_2, \cdots, A_n: D_n)\), R étant le nom de la relation et les \(A_i\), deux à deux distincts, les noms d'attributs. 3. Un élément de cette relation est un nuplet \((a_1, a_2, \cdots, a_n)\), les \(a_i\) étant les valeurs des attributs.
Et en ce qui concerne le vocabulaire, le tableau suivant montre celui, rigoureux, issu de la modélisation mathématique et celui, plus vague, correspondant à la représentation par table. Les termes de chaque ligne seront considérés comme équivalents, mais on privilégiera les premiers qui sont plus précis.
| Terme du modèle | Terme de la représentation par table |
|---|---|
| Relation | Table |
| nuplet | ligne |
| Nom d'attribut | Nom de colonne |
| Valeur d'attribut | Cellule |
| Domaine | Type |
Attention à utiliser ce vocabulaire soigneusement, sous peine de confusion. Ne pas confondre par exemple le nom d'attribut (qui est commun à toute la table) et la valeur d'attribut (qui est spécifique à un nuplet).
La structure utilisée pour représenter les données est donc extrêmement simple. Il faut insister sur le fait que les valeurs des attributs, celles que l'on trouve dans chaque cellule de la table, sont élémentaires : entiers, chaînes de caractères, etc. On ne peut pas avoir une valeur d'attribut qui soit un tant soit peu construite, comme par exemple une liste, ou une sous-relation. Les valeurs dans une base de données sont dites atomiques (pour signifier qu'elles sont non-décomposables, rien de toxique a priori). Cette contrainte conditionne tous les autres aspects du modèle relationnel, et notamment la conception, et l'interrogation.
Une base bien formée suit des règles dites de normalisation. La forme normale minimale est définie ci-dessous.
Définition : première forme normale
Une relation est en première forme normale si toutes les valeurs d'attribut sont connues et atomiques et si elle ne contient aucun doublon.
Un doublon n'apporte aucune information supplémentaire et on les évite donc. En pratique, on le fait en ajoutant des critères d'unicité sur certains attributs, la clé.
On considère pour l'instant que toutes les valeurs d'un nuplet sont connues. En pratique, c'est une contrainte trop forte que l'on sera amené à lever avec SQL, au prix de quelques difficultés supplémentaires.
Mais que représente une relation ?¶
En première approche, une relation est simplement un ensemble de nuplets. On peut donc lui appliquer des opérations ensemblistes : intersection, union, produit cartésien, projection, etc. Cette vision se soucie peu de la signification de ce qui est représenté, et peut mener à des manipulations dont la finalité reste obscure. Ce n'est pas forcément le meilleur choix pour un utilisateur humain, mais ça l'est pour un système qui ne se soucie que de la description opérationnelle.
Dans une seconde approche, plus "sémantique", une relation est un mécanisme permettant d'énoncer des faits sur le monde réel. Chaque nuplet correspond à un tel énoncé. Si un nuplet est présent dans la relation, le fait est considéré comme vrai, sinon il est faux.
La table des départements sera ainsi interprétée comme un ensemble
d'énoncés: "Le département de l'Ardèche a pour code 07", "Le
département du Gard a pour code 30", et ainsi de suite. Si un nuplet,
par exemple, (Gers 32), n'est pas dans la base, on considère que
l'énoncé "Le département du Gers a pour code 32" est faux.
Cette approche mène directement à une manipulation des données fondée sur des raisonnements s'appuyant sur les valeurs de vérité énoncées par les faits de la base. On a alors recours à la logique formelle pour exprimer ces raisonnements de manière rigoureuse. Dans cette approche, qui est à la base de SQL, interroger une base, c'est déduire un ensemble de faits qui satisfont un énoncé logique (une "formule"). Selon ce point de vue, SQL est un langage pour écrire des formules logiques, et un système relationnel est (entre autres) une machine qui effectue des démonstrations.